DNN 優化技巧與過擬合
範例程式:![]()
前一章的 Simple Dense DNN 已經比 SVM baseline 更好,但測試準確率仍有提升空間。本章透過神經網路優化技巧,觀察模型如何一步步改善,也同時學習如何判斷過擬合。
1. 為什麼需要優化?
建立神經網路不只是把層數堆起來。模型表現會受到許多因素影響,例如:
- 隱藏層寬度與深度。
- 激勵函數。
- batch size。
- learning rate。
- learning rate schedule。
- EarlyStopping。
- Dropout 或 L2 regularization。
這些設定會影響模型是否能順利收斂,也會影響模型是否只是在訓練資料上背答案。
2. 從 Simple DNN 到 Optimized DNN
本章採用的優化方向是:
- 保留 Dense DNN 架構,讓比較集中在訓練技巧。
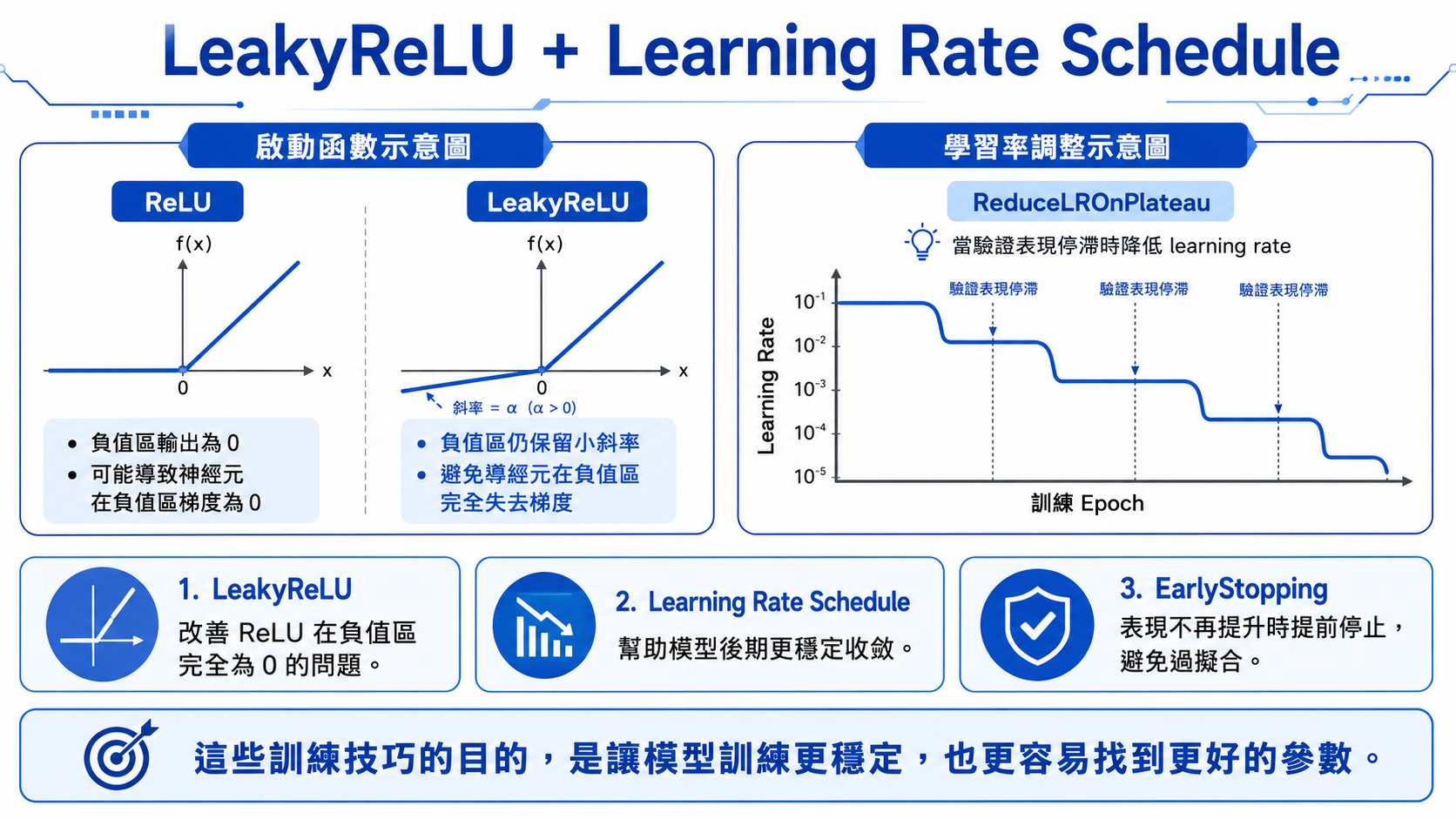
- 使用
LeakyReLU取代一般 ReLU。 - 使用 batch size 64。
- 使用
ReduceLROnPlateau,當驗證集表現停滯時降低 learning rate。 - 使用
EarlyStopping,避免模型在驗證表現不再改善後繼續訓練。
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(32, 32, 3)),
tf.keras.layers.Rescaling(1./255),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512),
tf.keras.layers.LeakyReLU(negative_slope=0.1),
tf.keras.layers.Dense(256),
tf.keras.layers.LeakyReLU(negative_slope=0.1),
tf.keras.layers.Dense(128),
tf.keras.layers.LeakyReLU(negative_slope=0.1),
tf.keras.layers.Dense(10, activation='softmax')
])
3. Learning Rate Schedule
learning rate 決定模型每次更新參數時走多大一步。太大可能震盪,太小可能學得太慢。
ReduceLROnPlateau 的想法是:如果驗證集表現一段時間沒有改善,就把 learning rate 降低,讓模型用更細緻的步伐繼續尋找較好的解。
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(
monitor='val_accuracy',
factor=0.5,
patience=3,
min_lr=1e-6
)
4. EarlyStopping
當模型在訓練資料上越來越好,但驗證資料不再改善時,繼續訓練可能只是讓模型更熟悉訓練資料,而不是學到更能泛化的規則。
EarlyStopping 可以在驗證表現停滯時提前停止訓練,並還原到最佳權重。
early_stop = tf.keras.callbacks.EarlyStopping(
monitor='val_accuracy',
patience=8,
restore_best_weights=True
)
5. 模型結果觀察
目前 notebook 的結果如下:
| 模型 | Train Accuracy | Test Accuracy |
|---|---|---|
| SVM RBF raw pixels | 0.6947 | 0.5170 |
| Simple Dense DNN | 0.7476 | 0.6540 |
| Optimized Dense DNN | 0.8501 | 0.6973 |
優化後的 Dense DNN 測試準確率提升到 0.6973,代表訓練技巧確實帶來改善。不過訓練準確率與測試準確率之間仍有明顯差距,這也提醒我們:模型可能已經開始對訓練資料過度貼合。
6. 避免過擬合的常見方法
若希望進一步降低 train/test gap,可以嘗試:
- 加入 Dropout。
- 加入 L2 regularization。
- 使用資料增強,例如隨機平移、旋轉、亮度變化。
- 減少模型參數量。
- 增加訓練資料量。
- 使用更適合影像資料的模型架構。
Info
對影像任務來說,最後一點非常重要。Dense DNN 把圖片攤平成一維向量,會破壞圖片的空間結構;CNN 則能保留局部像素關係,因此更適合影像辨識。
7. 小結
本章透過 LeakyReLU、learning rate schedule 與 EarlyStopping,讓 Dense DNN 有明顯改善。但 Dense DNN 仍然不是影像辨識的最佳架構。下一章我們會使用 CNN,觀察模型如何利用影像的空間結構取得更好的效果。