第一個 TensorFlow Dense DNN
範例程式:![]()
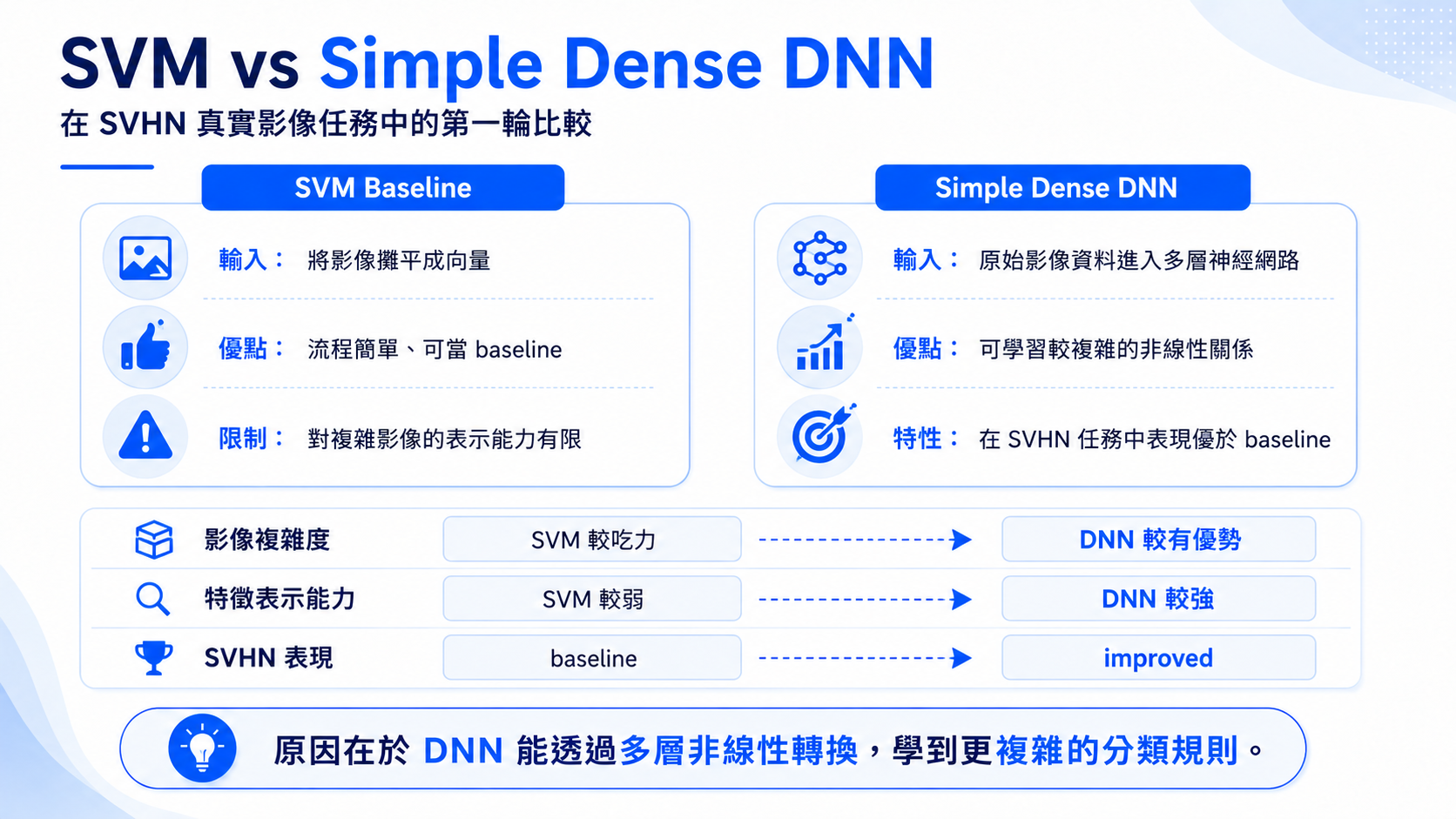
前一章我們使用 SVM 處理 SVHN 數字分類,發現傳統機器學習在真實影像資料上開始遇到限制。本章正式進入神經網路,使用 TensorFlow/Keras 建立第一個 Dense DNN 模型。

1. 神經網路在學什麼?
神經網路可以被理解成一個可調整的函數。模型一開始不懂資料,只能根據隨機初始化的參數做出預測。訓練的過程,就是讓模型根據錯誤逐步調整參數,讓下一次預測更接近正確答案。
一個基本訓練流程如下:
2. Dense DNN 的核心元件
| 元件 | 說明 |
|---|---|
Flatten |
將圖片攤平成一維向量 |
Dense |
全連接層,每個神經元都接收前一層所有輸入 |
| Activation | 讓模型可以學習非線性關係 |
| Loss | 衡量模型預測和正確答案的差距 |
| Optimizer | 根據 loss 調整模型參數 |
| Epoch | 訓練資料被模型完整看過幾輪 |
3. 建立 Simple Dense DNN
本章使用的模型是一個簡單但完整的 Dense DNN:
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(32, 32, 3)),
tf.keras.layers.Rescaling(1./255),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
這個模型會先將 RGB 圖片正規化,再攤平成一維向量,接著通過多層 Dense layer,最後輸出 10 個類別的機率。
Note
softmax 常用於多類別分類。它會將輸出轉換成機率分布,10 個類別的機率總和為 1,模型會選擇機率最高的類別作為預測結果。
4. 編譯模型
在 TensorFlow/Keras 中,建立模型後需要先進行 compile,指定 loss、optimizer 與評估指標。
這裡使用 sparse_categorical_crossentropy,是因為標籤是整數類別,例如 0、1、2,而不是 one-hot encoding。
5. 模型結果觀察
在目前 notebook 的設定下,Simple Dense DNN 的結果如下:
| 模型 | Train Accuracy | Test Accuracy |
|---|---|---|
| SVM RBF raw pixels | 0.6947 | 0.5170 |
| Simple Dense DNN | 0.7476 | 0.6540 |
可以看到 Dense DNN 相比 SVM 有明顯改善。這代表神經網路能從資料中學到更有用的表示方式,即使只是將圖片攤平成一維向量,也能比傳統 baseline 更進一步。
6. 小結
本章完成了第一個 TensorFlow DNN 影像分類模型,也看見了 DNN 相較 SVM 的提升。不過,Simple Dense DNN 的表現仍未達到非常理想。下一章我們會加入神經網路優化技巧,觀察模型是否能繼續進步。