前言
隨著人工智慧(AI)技術的迅速發展,AI 模型的應用場景越來越多樣化,這也導致對硬體性能和計算效率的需求日益增加。在這樣的背景下,AI 編譯器的概念逐漸受到重視。AI 編譯器的出現,為如何更有效率地運行 AI 模型提供了一種嶄新的解決方案。本篇文章將帶您了解 AI 編譯器的基本原理與設計,並探討其重要性以及與傳統編譯器的不同之處。
人工智慧(AI)編譯器
AI 編譯器是一種專門為 AI 模型而設計的編譯工具,其目的是將高階的 AI 模型轉換成適合特定硬體運行的優化程式碼。無論是深度學習模型還是其他機器學習模型,AI 編譯器都會根據目標硬體的特性進行針對性的優化,使模型能夠在硬體上達到更高的效能。例如,AI 編譯器可以優化計算圖、進行操作融合,或分配硬體資源以確保不同計算單元的有效利用。
為什麼需要 AI 編譯器?
AI 模型通常涉及大量的矩陣運算和複雜的計算圖,如果直接將這些模型在硬體上執行,可能無法充分利用硬體的計算潛力。AI 編譯器的設計目標正是解決這個問題。它能自動將 AI 模型轉換成適合硬體的優化表示,無論是針對 CPU、GPU 還是專用 AI 加速器,都能使其達到最優的執行效能。此外,AI 編譯器還能讓開發者無需深入了解底層硬體細節,並降低開發成本並加速模型的部署。
AI 編譯器與傳統編譯器的不同
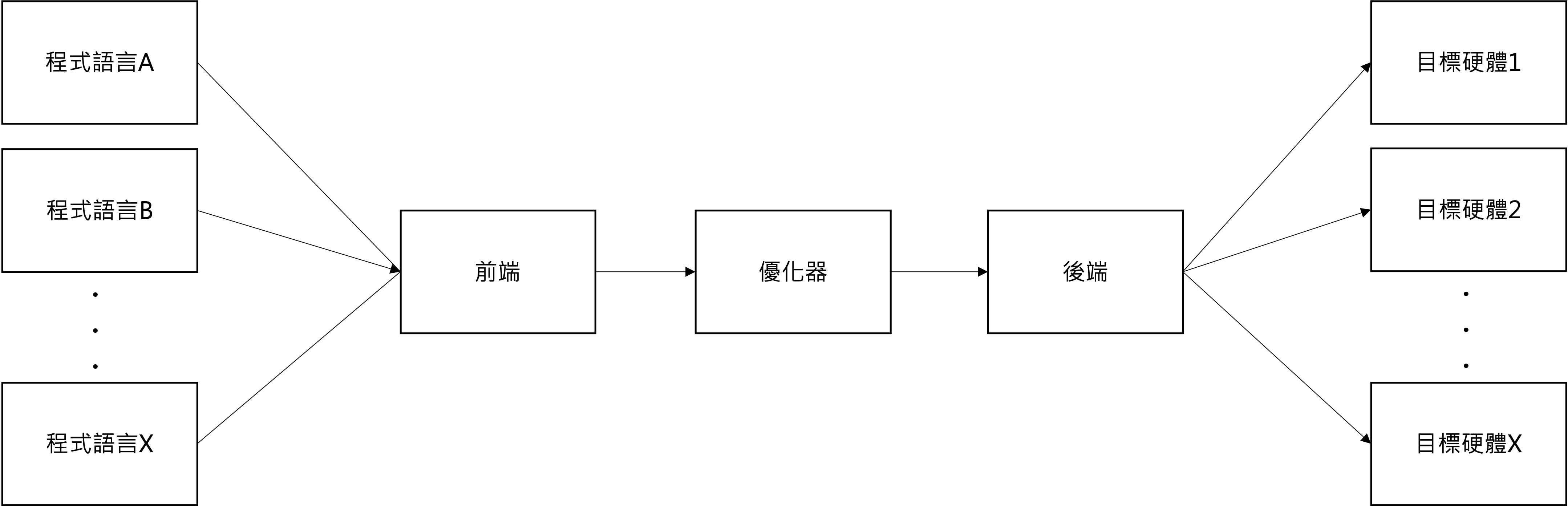
我們熟知的編譯器的主要功能是將高階語言(如 C/C++ 或 Java)撰寫的程式碼,轉譯為機器可以直接執行的機器碼。各 AI 訓練框架訓練出來的模型要如何部署到不同的硬體,就需要 AI 編譯器來解決。而 AI 編譯器的設計理念受到主流編譯器(如 LLVM)的啟發。為了更清楚地了解 AI 編譯器的運作,我們可以先透過下圖理解 LLVM 編譯器的架構。
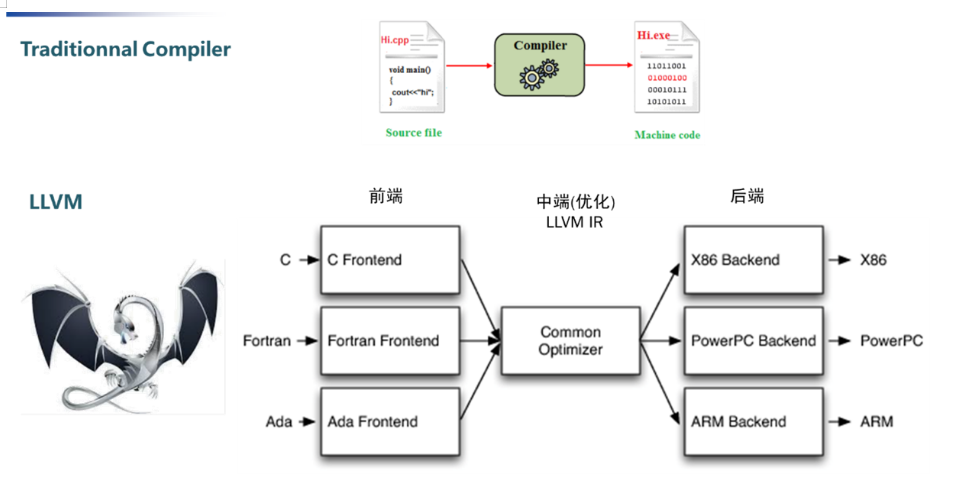
典型的編譯器架構通常分為三個部分:Frontend(前端解析器)、Optimizer(優化器)、Backend(後端程式碼生成器)。
- Frontend:負責將原始碼解析成語法樹或其他適合的結構,方便後續處理。
- Optimizer:進行程式優化,找出可以簡化或改進的邏輯,以提升執行效率,例如刪除無意義的指令(如
a = a + 0)。 - Backend:將經過優化的邏輯轉換為目標平台的低階機器碼,生成可執行的二進位檔案。
LLVM 中的核心概念是其通用的中介表示法(Intermediate Representation, LLVM IR)。LLVM IR 是一種接近機器語言的中間語言,為了增強通用性與靈活性而進行了簡化。整個 LLVM 編譯過程中,各部分都基於 LLVM IR 進行工作:
- Frontend 將原始程式碼轉換為 LLVM IR。
- Optimizer 將 LLVM IR 優化為執行效率更高的版本。
- Backend 根據 LLVM IR 生成特定平台的機器語言。
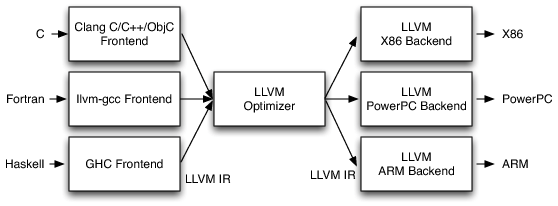
圖源:LLVM 編譯器架構
這種結構化的設計讓 LLVM 能夠支援多種語言與硬體平台,同時也為 AI 編譯器的開發提供了寶貴的參考範例。而 AI 編譯器則是將 AI 模型(如 TensorFlow 或 PyTorch 的模型)轉換為針對特定硬體優化的運算圖。AI 編譯器需要考慮深度學習特有的運算,例如矩陣乘法、非線性激發函數等,並對這些操作進行融合和優化,以提升運行效率。此外,AI 編譯器還涉及模型量化、剪枝等技術,進一步縮減模型大小並加速推論。讓我們進一步比較深度學習編譯器與傳統編譯器(如 LLVM)在結構上的異同。
- Frontend 負責解析深度學習框架的模型,將其轉換為 High-Level IR,作為編譯器進一步優化的基礎。
- Optimizer 對 High-Level IR 進行高階優化(如算子融合、靜態形狀推斷等),以提升模型的執行效率。
- Backend 將經過優化的 High-Level IR 轉換為硬體相關的低階指令,通過 Compiler Backend 和代碼生成(Code Gen)生成 Low-Level IR。
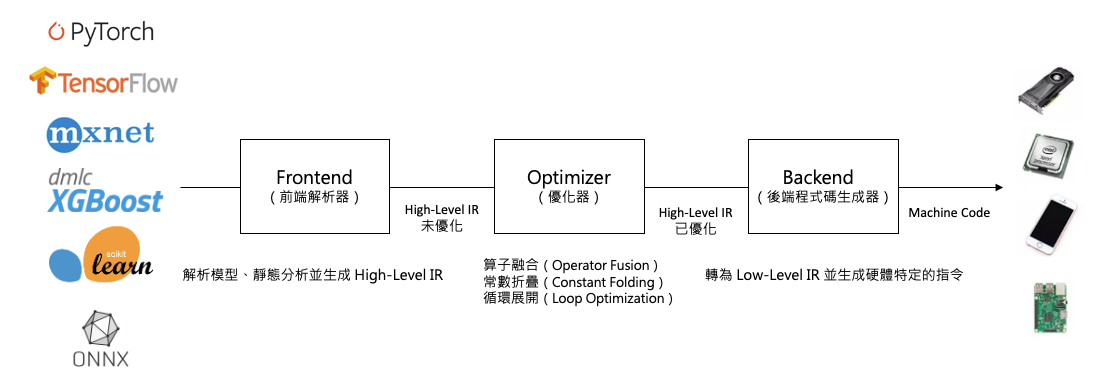
AI 編譯器的基本設計與原理
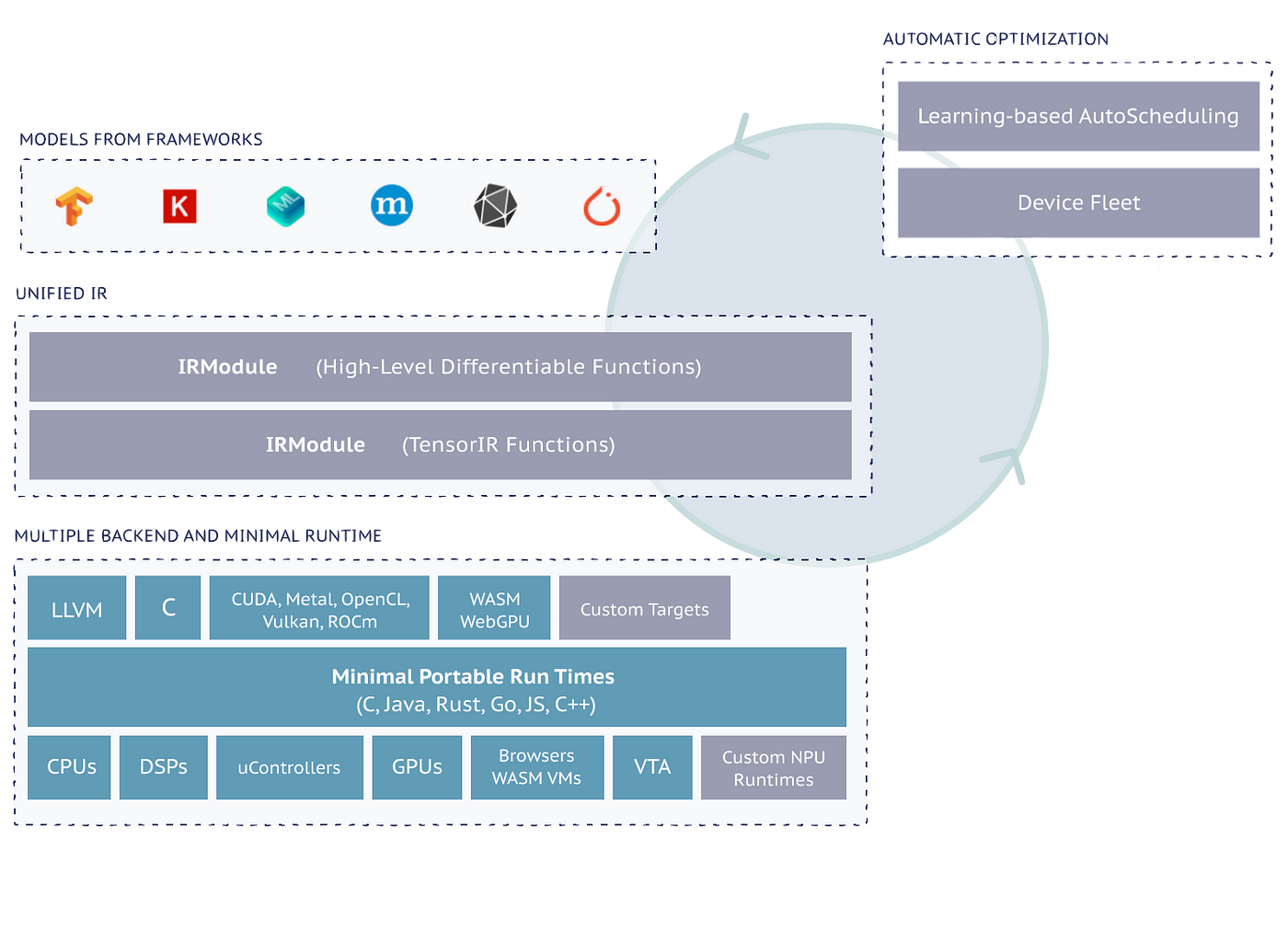
AI 編譯器通常統稱為 深度學習編譯器(Deep Learning Compiler)。這些工具的主要目的是將高階的機器學習模型(例如從 TensorFlow、PyTorch、ONNX 等框架中導出的模型)編譯、優化,並轉換為可以在特定硬體(如 CPU、GPU、TPU、嵌入式設備)上高效運行的機器碼。

AI 編譯器的基本結構通常包括前端、優化器和後端三個部分。前端負責接收用戶的模型並將其轉換為中間表示(Intermediate Representation, IR)。優化器對 IR 進行多層次的優化,例如操作融合和數據流優化。最後,後端根據硬體特性將優化後的 IR 轉換為具體的機器碼,以便在目標硬體上高效執行。在這些過程中,AI 編譯器會根據硬體的特性(如計算能力、記憶體大小、特殊運算單元)進行針對性的優化。
借鑑傳統編譯器的概念,AI 編譯器的輸入為深度學習訓練框架所產生的模型定義文件,輸出則為能在不同硬體上高效執行的機器碼。其架構由上至下分為四個層級:
1. 模型對接層
- 支援多種深度學習框架(如 TensorFlow、Caffe、PyTorch、MxNet)所訓練的演算法模型輸入。
2. 圖層層級(High-Level IR)
- 以計算圖的方式表示神經網路結構(例如 Relay IR 或 MLIR),執行與硬體和框架無關的優化操作,包括算子融合、記憶體分配優化、資料類型和維度推導等。
3. 算子層級(Operator/Kernel Level)
- 聚焦於張量運算,透過硬體專用的算子庫(如 Intel MKL、NVIDIA cuDNN、TensorRT)實現高效運算,並支援不同硬體後端的算子實作。
- 利用機器學習方法探索最佳的程式碼生成策略,針對特定硬體進行深度優化。
- 輸出適配特定硬體的低階中間表示(Low-Level IR),(如 CUDA Kernel、OpenCL Kernel 或 LLVM IR 等),以實現更高效的執行。
4. 硬體後端
- 支援多種硬體架構,包括 GPU、ARM CPU、x86 CPU、NPU 等,針對不同硬體特性進行深度優化。
- 輸出適配目標硬體的高性能執行機器碼,並生成相應的二進位檔案(如 .elf、.so 或可執行文件)。
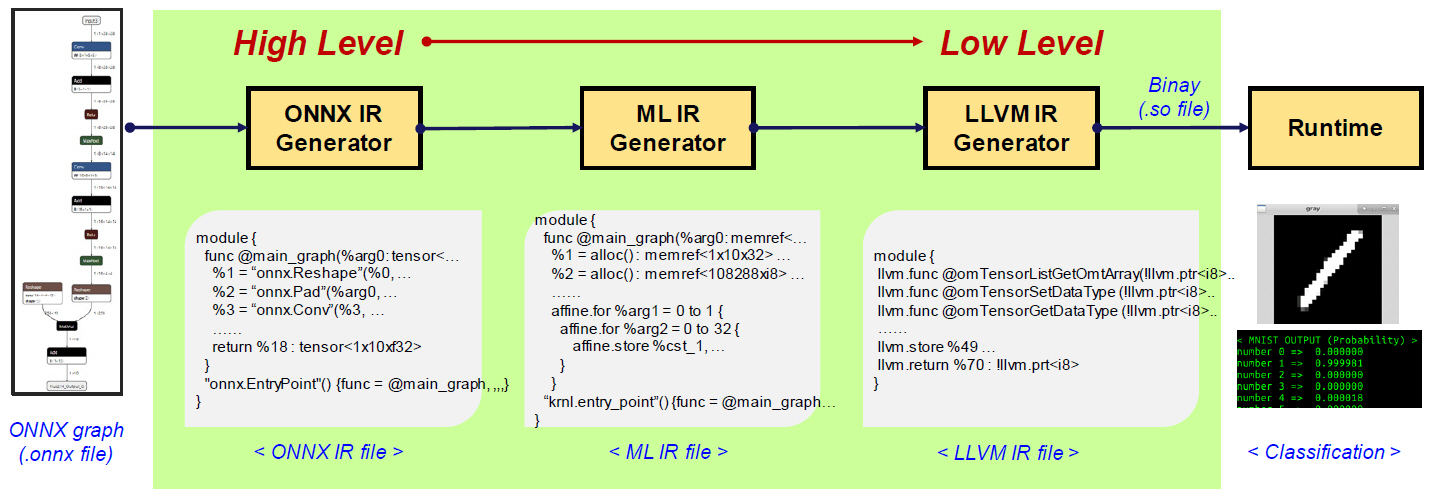
如上圖所示,ONNX-MLIR 是基於 LLVM 的模組化設計理念,充分利用 LLVM 強大的中間表示(IR)和優化基礎設施,實現對 ONNX 模型的高效編譯。這種設計方式讓 ONNX-MLIR 能夠將 ONNX 格式的模型轉譯為針對特定硬體架構深度優化的機器碼(如二進位文件)。
除此之外,還有像 TVM 這類主流的深度學習編譯器框架,專注於將深度學習模型高效轉換為能在多種硬體上執行的優化程式碼。TVM 提供了端到端的編譯工作流程,從模型的高階表示到針對硬體架構的低階程式碼生成,涵蓋了自動調度、自動最佳化以及高性能機器碼的輸出,廣泛支援包括 GPU、CPU 和專用加速器(如 NPU)等多種硬體平台。
| 層級 | 功能描述 | 相關工具 |
|---|---|---|
| 模型對接層 | 支援多框架模型的導入,並轉換為統一的中間格式 | TensorFlow、PyTorch、ONNX、MxNet 等 |
| 圖層層級 | 高層圖的表示與優化,執行與硬體無關的操作,如算子融合與記憶體分配優化 | Relay IR(TVM)、MLIR(LLVM)、TensorFlow XLA、ONNX IR |
| 算子層級 | 張量運算的硬體加速實現,依賴專用算子庫與自動排程(Auto Scheduler) | NVIDIA cuDNN、Intel oneDNN、TensorRT、ROCm、ARM Compute Library、TVM AutoTVM、Ansor |
| 硬體後端 | 生成針對 GPU、CPU、NPU、FPGA 等硬體的執行機器碼與二進位檔案 | LLVM、CUDA、Metal、ROCm、OpenCL、FPGA 工具鏈(Quartus、Vitis HLS)、Google TPU 工具鏈 |
中間表示(IR)基礎概念
中間表示(Intermediate Representation, IR)是 AI 編譯器中一個非常重要的概念,位於高階模型表示(如神經網路模型)與最終硬體機器碼之間的中間層。IR 的設計需兼具多重目標:一方面要完整地保留 AI 模型的語義,確保原始功能不變;另一方面則需能支援各種優化操作,使其在實際執行時達到更高效的效能表現。
IR 通常以運算圖(Computation Graph)的形式呈現,其中包含 節點(Node) 和 邊(Edge)。每個節點對應一個具體的運算操作,例如矩陣乘法、卷積運算或激活函數等;而邊則表示節點之間的數據流動,描述了運算操作的輸入與輸出關係。這種結構化的表示方式能清晰地描述模型的計算流程,便於進行後續的分析與優化。
透過 IR,AI 編譯器能在多層次上進行效能優化,常見的優化技術包括但不限於以下幾種:
-
運算融合(Operation Fusion)
將多個連續的運算合併為單一運算,以減少記憶體讀寫和運算開銷。 -
數據排程(Data Scheduling)
根據硬體特性調整數據處理順序,提升記憶體存取效率。 -
重排序(Reordering)
調整運算順序以利用硬體平行計算能力,進一步縮短執行時間。 -
量化(Quantization)
將浮點數據壓縮為低精度整數格式,以減少記憶體使用和運算資源需求。 -
記憶體管理(Memory Optimization)
優化中間數據的分配與釋放,減少記憶體佔用。
小結
AI 編譯器對於 AI 模型的高效執行扮演重要的角色。透過將 AI 模型轉換為適合特定硬體的優化程式碼,AI 編譯器使得模型運行得更加高效,並降低了開發的複雜度。隨著 AI 編譯技術的不斷發展,我們可以期待 AI 應用的開發和部署變得更加便捷和高效。
Reference
- openmlsys AI編譯器與前端技術
- AIoT 深度學習模型的編譯與 Edge 部署
- 簡報:Introduction to the TVM Open Source Deep Learning Compiler Stack
 https://www.youtube.com/channel/UCSNPCGvMYEV-yIXAVt3FA5A
https://www.youtube.com/channel/UCSNPCGvMYEV-yIXAVt3FA5A