當進行 CI/CD 流程自動化時,許多人會選擇使用 Jenkins 來執行測試任務,而 GitLab 則作為程式碼版本控制系統及 CI/CD Pipeline 平台。本文將詳細介紹如何設置一個流程,使得 GitLab 的 Push 事件觸發 Jenkins 執行單元測試,並在測試成功後,由 Jenkins 進一步觸發 GitLab 的 Pipeline。
目標
- 當 Push code 到 GitLab 時,自動觸發 Jenkins 進行單元測試。
- 測試通過後,(當有Release Tag Push時)由 Jenkins 觸發 GitLab 的 CI/CD Pipeline,執行 .gitlab-ci.yml。
事前準備
- GitLab 專案:擁有一個已經設定好的 GitLab 專案,並在專案根目錄擁有 .gitlab-ci.yml。
- Jenkins 伺服器:安裝並配置好的 Jenkins 伺服器,且已安裝 GitLab 插件。
操作說明
步驟 1:設定 GitLab 的 Webhook 觸發 Jenkins 任務
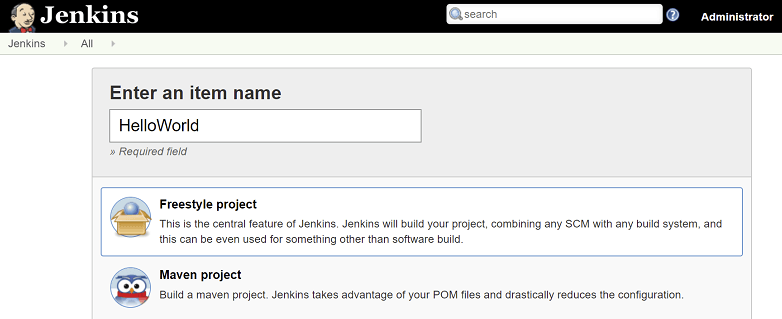
1. 在 Jenkins 新增一個 Freestyle Job
首先,我們需要在 Jenkins 上建立一個 Freestyle Job,當 GitLab 有代碼推送時,這個任務會自動執行。
具體步驟:
- 登入 Jenkins,點擊「新建任務(New Item)」。
- 輸入專案名稱,選擇「Freestyle 專案」。
- 點擊「確定(OK)」來建立這個 Jenkins Job。
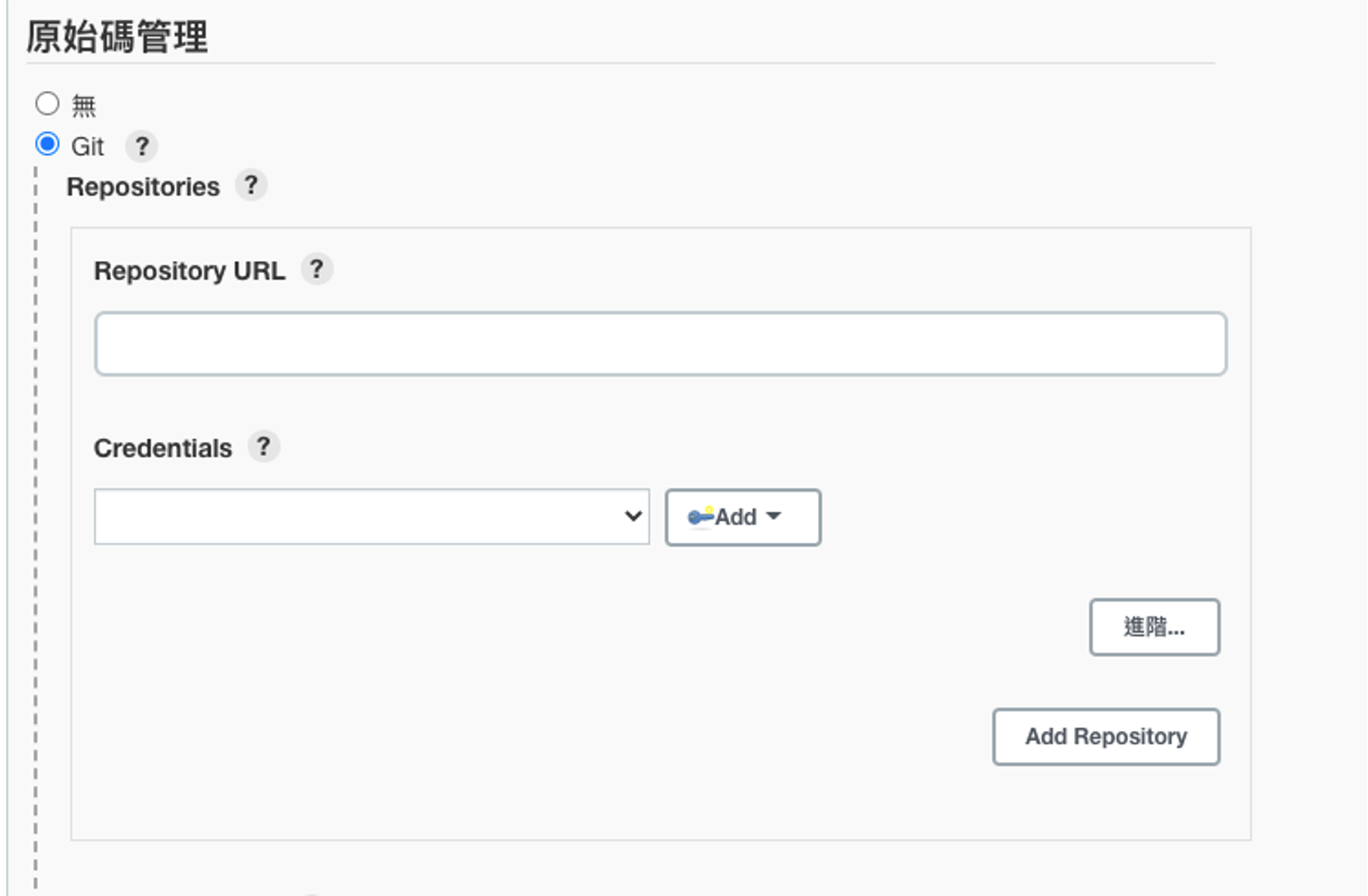
2. 設定 GitLab Repository URL 與憑證
設定專案的來源代碼管理,讓 Jenkins 知道它應該從哪裡拉取代碼來進行測試。
具體步驟:
- 在新建立的 Jenkins 任務設定頁面中點選「組態」,找到「來源代碼管理(Source Code Management)」區域,選擇 Git。
- 在 Repository URL 欄位中,填寫你 GitLab 專案的 clone URL(HTTPS 或 SSH 都可以)。
- 在「Credentials」欄位中,選擇你的憑證。如果還未設定憑證,點擊「新增」並選擇正確的 GitLab 帳密或憑證。
3. 設定 Jenkins 任務的觸發條件
我們需要配置 Jenkins 任務,使其在 GitLab 有代碼推送時自動觸發。
具體步驟:
- 在任務配置頁面中,找到「建置觸發程序(Build Triggers)」區域。
- 勾選「Build when a change is pushed to GitLab」,這樣當 GitLab 有新的代碼推送時,Jenkins 任務就會被自動觸發。
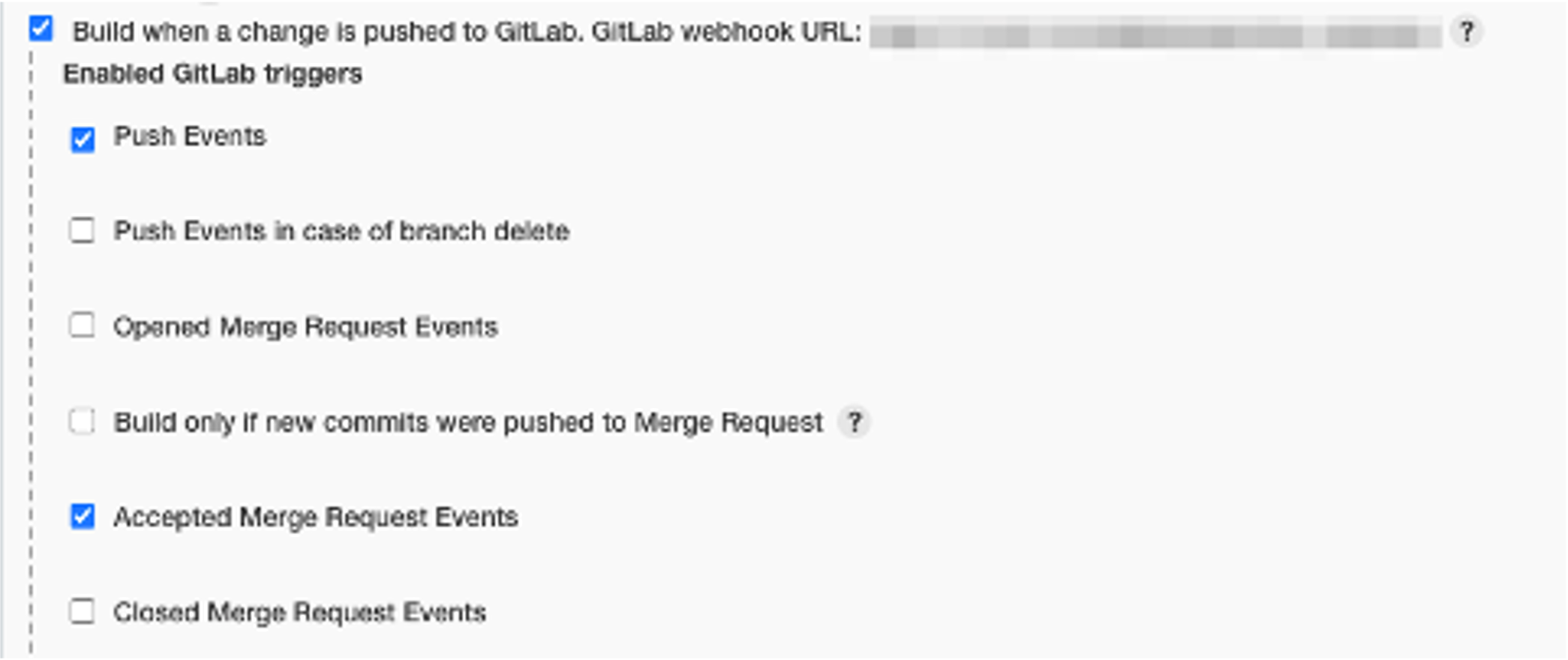
若建置觸發程序中無GitLab選項,即代表該環境中尚未安裝插件。 請在Jenkins主頁面中選擇管理
Jenkins > System Configuration中的Plugins 查詢「GitLab」,並下載安裝所有相關的插件。
4. 登入 GitLab,設定 Webhook
現在我們需要在 GitLab 中設定一個 Webhook,將 GitLab 推送的變更通知 Jenkins,從而觸發剛剛建立的 Jenkins Job。
具體步驟:
- 登入你的 GitLab 專案。
- 進入「設定(Settings)」 >「 Integrations」 頁面並找到 Jenkins。

- 在「URL」欄位中,輸入 Jenkins 的 Webhook 地址,格式如下:
http://<jenkins-server>/project/<jenkins-job-name>
<jenkins-server>:替換成你的 Jenkins 伺服器 URL。<jenkins-job-name>:替換成你在 Jenkins 中創建的 Job 名稱
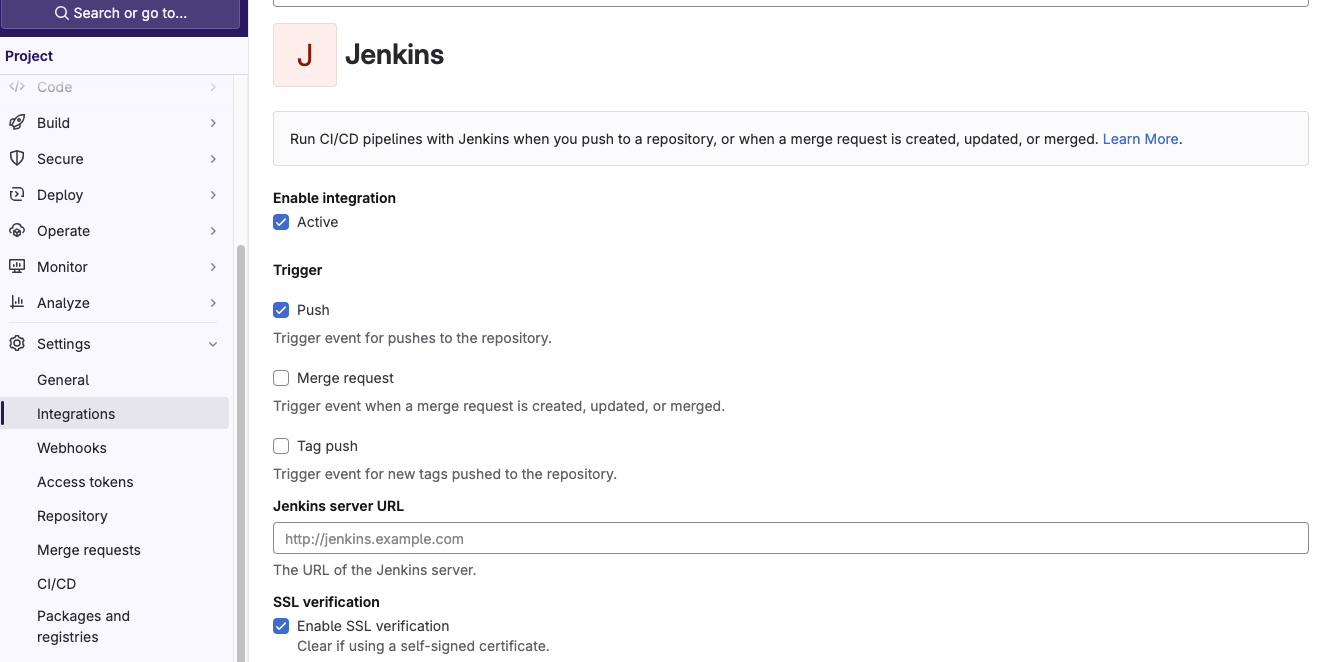
- 在「觸發事件(Trigger events)」區域,選擇「Push events」,這樣每當有人推送代碼到 GitLab 時,Webhook 都會通知 Jenkins。
- 設定完畢後可以點選「Test settings」,測試沒問題後即可點選儲存。
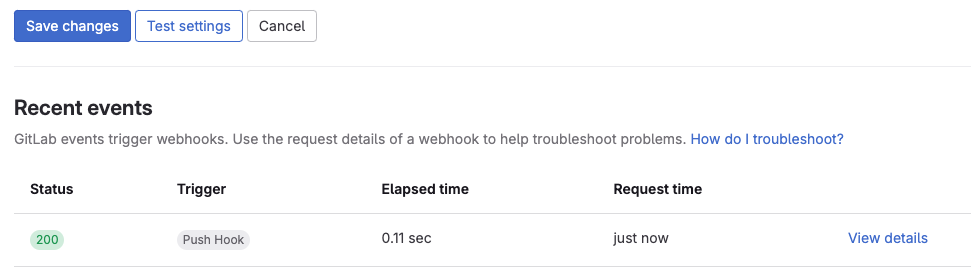
此時回到Jenkins專案中即可碼放發現剛剛手動觸發的測試已經連動到我們的Jenkins主機中。
以上設定成功後,當 Push code 到 GitLab 時,自動觸發 Jenkins 進行單元測試。 接著可以試著在GitLab推送一個新的commit,並觀察Jenkins是否會自動偵測有新的Push並觸發。
小結:
在這個步驟中,我們:
- 在 Jenkins 中建立了一個 Freestyle Job,並設定了它的 GitLab Repository URL 與憑證。
- 配置了 Jenkins 任務,使其在 GitLab 有新的代碼推送時自動觸發。
- 在 GitLab 中設定了 Webhook,使其能夠與 Jenkins 溝通並觸發任務。
這樣每當有人推送程式碼到 GitLab 時,Jenkins 就會自動執行你配置的單元測試或其他任務。接下來,我們要來設定測試與觸發 GitLab Pipeline 的後續流程。
步驟 2: 在 Jenkins 測試成功後觸發 GitLab Pipeline
當 Jenkins 單元測試成功後,我們希望 Jenkins 去觸發 GitLab Pipeline,這可以透過 GitLab 的 Trigger Token 來實現。首先,為了避免每次 Push code 後 GitLab 的 Pipeline 都自動執行,我們可以設定條件讓 GitLab 的 Pipeline 只在 Jenkins 測試成功後才被手動觸發。
1. 修改 .gitlab-ci.yml
在 GitLab 專案的 .gitlab-ci.yml 檔案中,使用 rules 來設定觸發條件,讓 GitLab Pipeline 不會在每次 push 時自動執行:
stages:
- test
- deploy
# 全局設定 pipeline 只接受特定來源的觸發
workflow:
rules:
- if: '$CI_PIPELINE_SOURCE == "push"'
when: never # 避免 push 時 GitLab 自動觸發 pipeline
- if: '$CI_PIPELINE_SOURCE == "trigger"'
when: always # 允許通過 API 觸發 pipeline
test_job:
stage: test
script:
- echo "Running tests..."
deploy_job:
stage: deploy
script:
- echo "Running deploy..."
- workflow:這個指令會全局控制 pipeline 的執行條件,適用於整個 pipeline(即所有的 job)。這樣可以避免在每個 job 中重複編寫 rules 條件。
- rules:我們定義了兩條規則:
- 當 pipeline 來源是 push 時,設定 when: never,表示不允許 push 事件觸發 pipeline。
- 當 pipeline 來源是 trigger 時,設定 when: always,允許通過 API 或觸發器來啟動 pipeline。
在你的
.gitlab-ci.yml檔案中確保加入 workflow 內容並設定執行條件。
2. 在 GitLab 中建立 Trigger Token
- 登入你的 GitLab 專案,進入「設定(Settings)」 > 「CI / CD」 > 「Pipeline trigger tokens」。
- 新增一個 Trigger,並記下 Token 值,這個 Token 將會在 Jenkins 中使用。
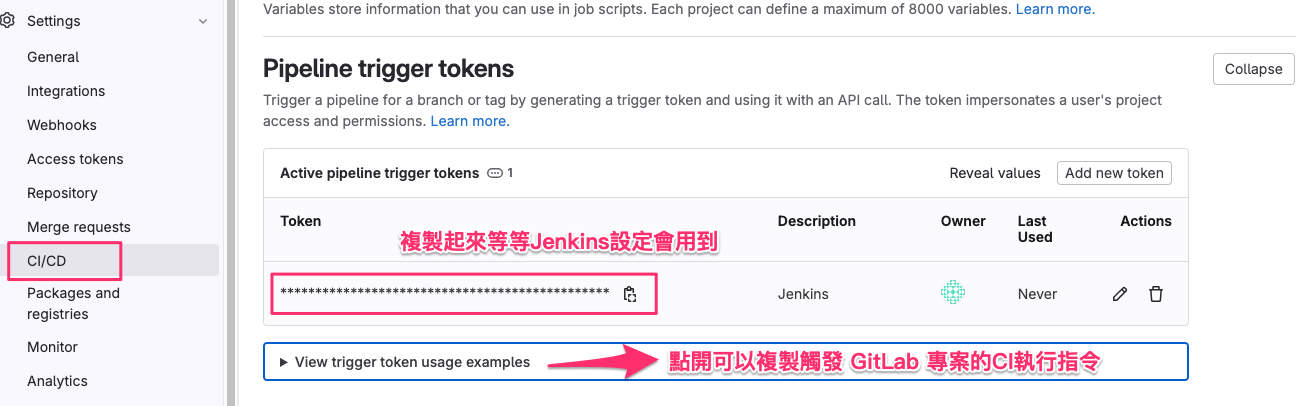
點選 View trigger token usage examples 可以取得完整 API 呼叫指令,Jenkins稍後設定會用到。
3. 在 Jenkins 中新增觸發 GitLab Pipeline 的步驟
在 Jenkins 的 job 中,當單元測試成功後,我們可以新增一個步驟來觸發 GitLab Pipeline。
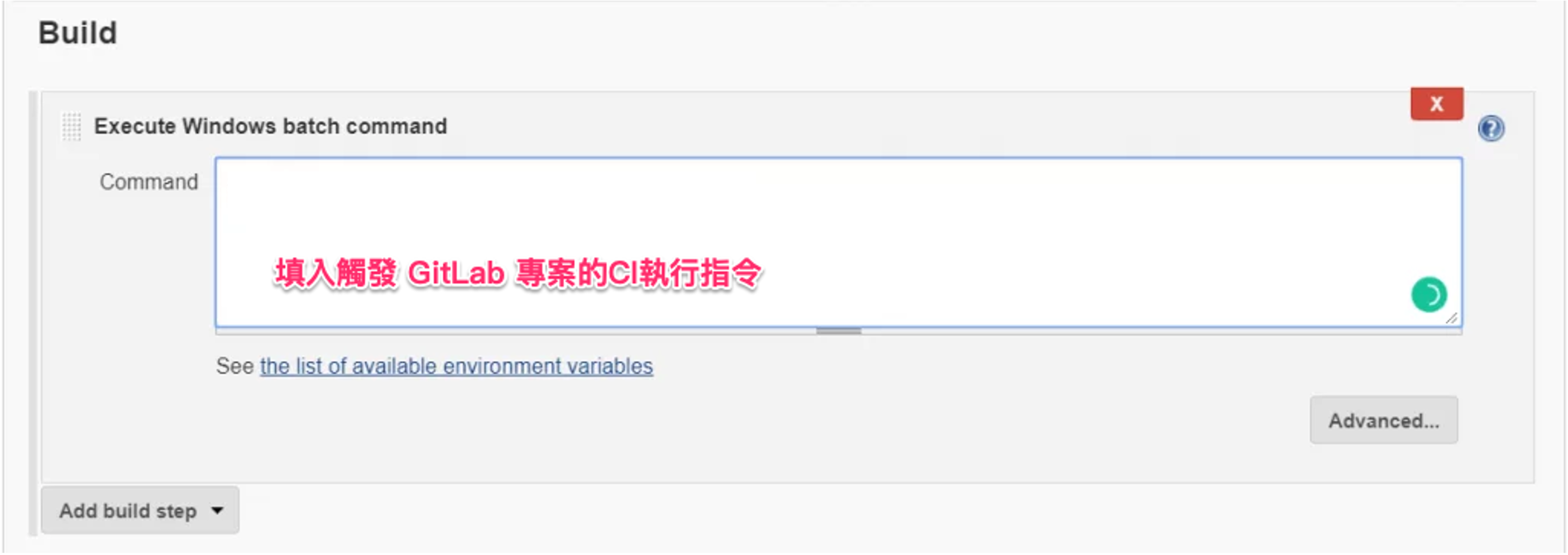
- 進入 Jenkins 專案頁面,點擊「組態」。
- 在「Build Steps」中,新增一個「執行 Windows 批次指令」步驟,並填入觸發 GitLab 專案的CI執行指令。格式如下:
curl -X POST --fail -F token=YOUR_TRIGGER_TOKEN -F ref=master https://gitlab.com/api/v4/projects/PROJECT_ID/trigger/pipeline
將 YOUR_TRIGGER_TOKEN 替換成你在 GitLab 中生成的 Trigger Token,PROJECT_ID 替換為 GitLab 專案的 ID(可以在 View trigger token usage examples 找到),ref 則是你要觸發的分支名稱,例如 main。
當 Jenkins Job 成功執行後,Jenkins 就會自動觸發 GitLab 的 Pipeline 來執行接下來的 CI/CD 流程。
在 README 文件中顯示 pipeline status / test coverage 標籤
前往 repository 的 Settings → CI / CD → General pipelines settings → 找到 Pipeline status 和 Coverage report。
將這兩段提供的 Markdown 語法複製到 README 中,這樣一進入 repository 就能看到專案的狀態。這些標籤對於不熟悉專案狀態的人來說非常有幫助,能快速了解 pipeline 和測試覆蓋率的情況。


