前言
此篇論文 Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting 獲得了 AAAI 2021 的最佳論文。其背景主要是解決長序列預測的問題,以實際的電力變壓器數據進行未來長時間的連續預測。長序列預測通常具有大量的歷史數據,隨著 LSTM 模型預測的輸出越長其運算速度將會越慢且錯誤越大。導致在有限的資源運算下會有比較有長時間的預測。因此本篇論文基於 self-attention 的優點,並改善 Attention 架構所面臨的三大瓶頸並提出了 Informer 模型。

Transformer 對於長序列預測所面臨的挑戰
對於以下這三個問題,作者提出 Informer 模型:
- 挑戰一: self-attention 點積運算使得每一層時間和空間複雜度都為O(L2)
- 挑戰二: 對於長序列的輸入,Encoder 和 Decoder 的堆疊對於記憶體負擔重,如果有 J 層就會有 O(J*L2)的記憶體使用。此特性限制了模型對於長序列的接收與處理。
- 挑戰三: 對於長序列的輸出,其運算速率會大幅下降。因為在原始 Transformer 的 Decoder 在預測的過程中是動態的輸出。也就是上一次的輸出做為下一次 Decoder 的輸入,然後再預測下一個輸出。這個過程使得 Transformer 預測的過程是和 RNN 一樣慢的。
[挑戰一] Self-attention 機制
經過研究發現 Attention map 的值在很多情況下是較為稀疏的。也就是大部分的注意力啟發了微微的作用。在傳統的 self-attention 有 Q、K、V。然後進行 Scaled Dot-Product Attention 計算,論文終將原始的 self-attention qi 拿出來重新寫成一個機率的形式。另外在傳統的 self-attention 需要有二次的時間複雜度的點積運算來計算公式中的機率p。另外先前也有提到 self-attention 具有稀疏性,他的分佈呈現常長尾分佈,也就是只有少數的點積對主要的注意力有貢獻。其他的點積可以忽略。我們用來評估第 i 個 Query 稀疏性的方法是 KL 散度。KL 散度是用來計算 q,此外 q 可使說是一個均勻的分佈的機率。另外 p 是注意力的機率,也就是選取每一個 Attention 的機率。經過 KL 散度可以計算他們兩個之間的相對熵。最後我們可以得到第 i 個 query 的稀疏性評估方式。在這個評估方式中我們希望計算出來的分數越大,那麼就意味著 KL 散度越大。也代表著 Attention 的機率和均勻分佈的機率其實是差得更遠的。
定義 ProbSparse self-attention
論文中定義了 ProbSparse self-attention,其中 Q bar 是和原本的 Q 具有相同大小的稀疏矩陣。他裡面只包含了 top-u 的 query。這個 top-u 是根據上面的評估方法 M(qi, k) 的公式所計算出來的。我們把這個 top-u 的 query 稱為 Active queries。u 的大小是透過採樣參數 c 來決定的。時間空間複雜度為 O(c log L)。
如果我們採取這種方式需要走一遍 qi ,然後取 top-u。那這裡我們必須選多少的 u 才合適?我們需要把這 L 個的 query M(qi, k) 的分數全都算出來後我們才能取 top-u。因此這裡還是需要 O(L2)的時間複雜度。另外紅框的 log-sum-exp 的方法有數值穩定性的問題(numerical stability issue),這是因為在計算過程中精度的截斷所帶來的問題。解決的方式為不加總所有exp數值,而是找出最大的來代替。其帶表是原本公式的 upper bound。
剛剛已經將 log-sum-exp 替換成 max。暫時可以解決數值穩定性問題,但還沒有解決計算量 O(L2)。在這個演算法一中其實我們不必去計算所有 L 個 Query。其實從裡面採樣 log L 個就足以代表擬合原始的分佈。透過這種方式複雜度從 L 平方降為 O(L log L)。
[挑戰二] Self-attention Distilling Operation
對於長序列的輸入問題,論文中提出了 self-attention 蒸餾的方法。在每一層 self-attention 的輸出加上 Conv1d 的卷積層再進行 MaxPool。使得 Feature Map 的尺寸能在時間維度上減半。也就是將原本的 LL 變成 (L/2)(L/2)。公式中的 AB 是 Attention Block 的縮寫。另外為了增加蒸餾的穩健性,增加了幾個並列了幾個副本。在主序列的長度 L,並複製一個減半後的序列L/2形成第一個副本。接下來第二個副本再砍半得到 L/4。透過這種方式我們得到若干個L/4的 Feature Map 。最後將其拼接起來作為 Encoder 的最終輸出。

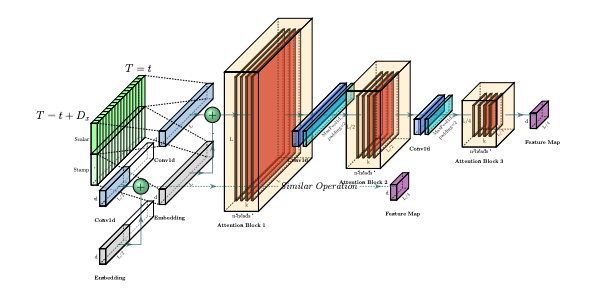
因為在第二個挑戰中在長序列的輸入所造成的資訊量龐大的問題,透過蒸餾的方法去減少 Feature Map 的大小。使得 Feature Map 並不會在空間上佔太多記憶體空間。
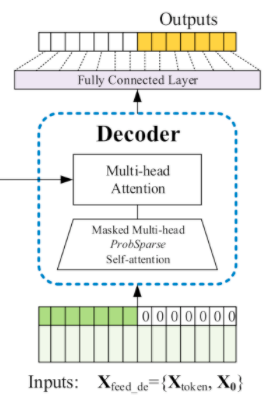
[挑戰三] Generative-style Decoder
第三個挑戰是長序列的輸出,因為 Transformer 無法有效率地去處理龐大的輸出。這是因為原始的 Transformer 輸出是一個 Dynamic encoding 的 Decoder,其特性是一個一個的輸出。就像一個 RNN 的模型一樣,必須得到目前的輸出才能預測下一個時間的的輸出。而我們知道 Start token 在 NLP 領域中是一個非常有效的方法。在本論文中也擴展了這個概念,應用於長序列輸出預測。針對長序列的輸出會一次性生成所有預測數據,不需要一步一步進行迭代。同時與 NLP 的不同之處是 Start token 並非特殊符號。而是從輸入的序列中採樣一個較短的序列,此序列為需要預測的序列之前的片段。舉個例子來說假如我們要預測5~10號的數值,我們必須要先從輸入中拿1~5號的值作為 Start token。然後告訴模型未來的五天一次預測輸出,透過這種方式我們就解決了第三個挑戰。
總結
最後我們來回顧一下 Informer 模型,整體來說我們是使用一個 Encoder 和 Decoder 的架構基於 Transformer。論文中提出 Probsparse self-attention、 self-attention Distilling 與 Generative-style Decoder。透過這三個技巧解決了 Transformer 對於長時間序列預測所會面臨的問題。
GitHub 程式碼: zhouhaoyi/Informer2020
鼓勵持續創作,支持化讚為賞!透過下方的 Like 拍手👏,讓創作者獲得額外收入~ https://www.youtube.com/channel/UCSNPCGvMYEV-yIXAVt3FA5A
https://www.youtube.com/channel/UCSNPCGvMYEV-yIXAVt3FA5A