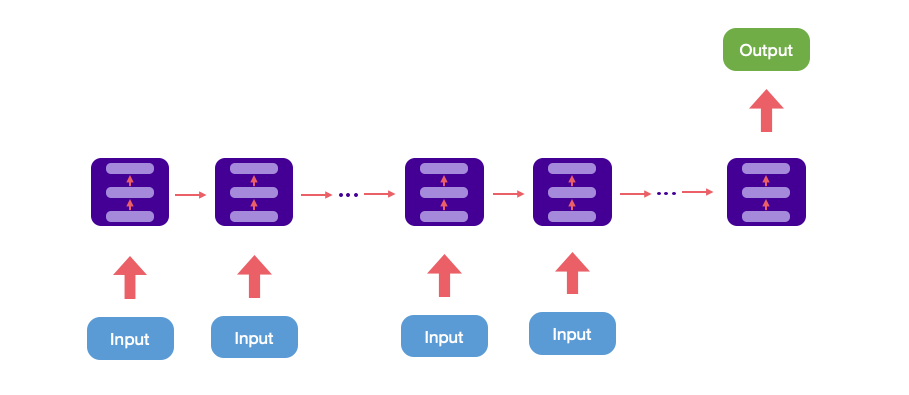
Many to one
輸入是一個序列,輸出是一個單獨的值。通常處理序列的分類問題,如識別一段文字是否褒貶,或者文字的感情傾向,判斷一段影片的類別等等。
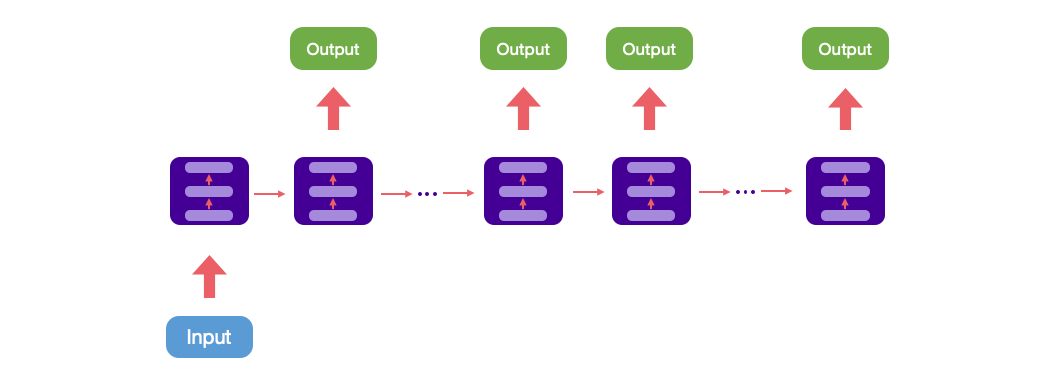
One to Many
由一個輸入當作起始點,序列開始並進行輸入計算,最終輸出為一個序列。
還有一種結構把輸入 x 作為每個階段的輸入。
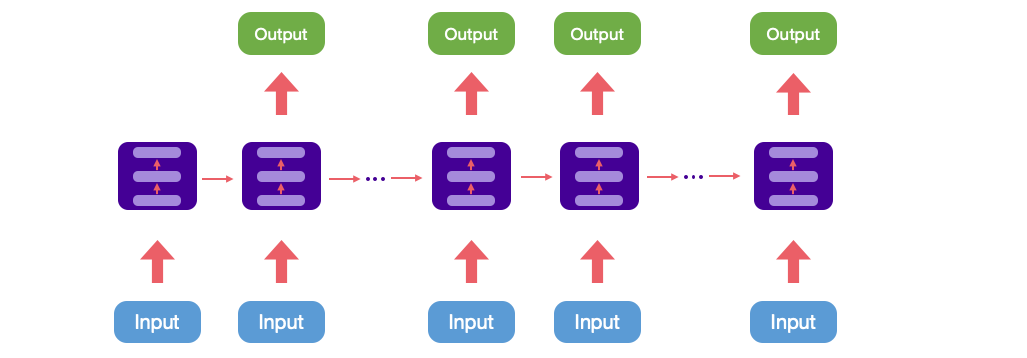
這種結構一般處理從圖像生成文字、文章生成、詩詞生成或是從類別生成音樂等。
Many to Many (Seq2seq)
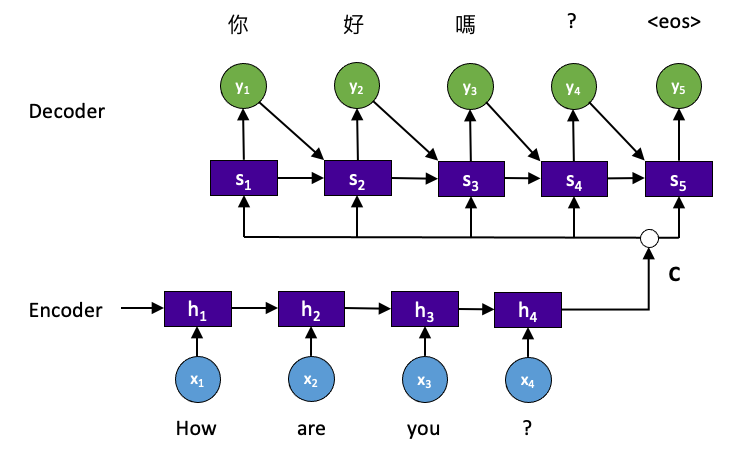
這種結構又叫Encoder-Decoder模型。先將輸入編碼(Encoder)為一個向量c,c的計算方式有很多。
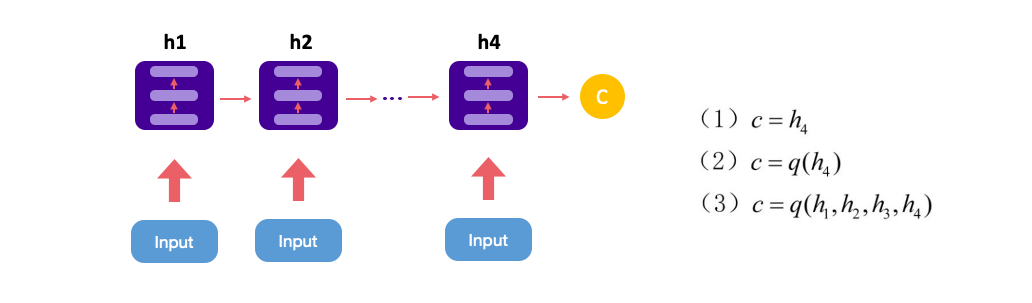
接下來對 c 做解碼(Decoder),即將 c 當做解碼部分的 h0 輸入到Decoder。
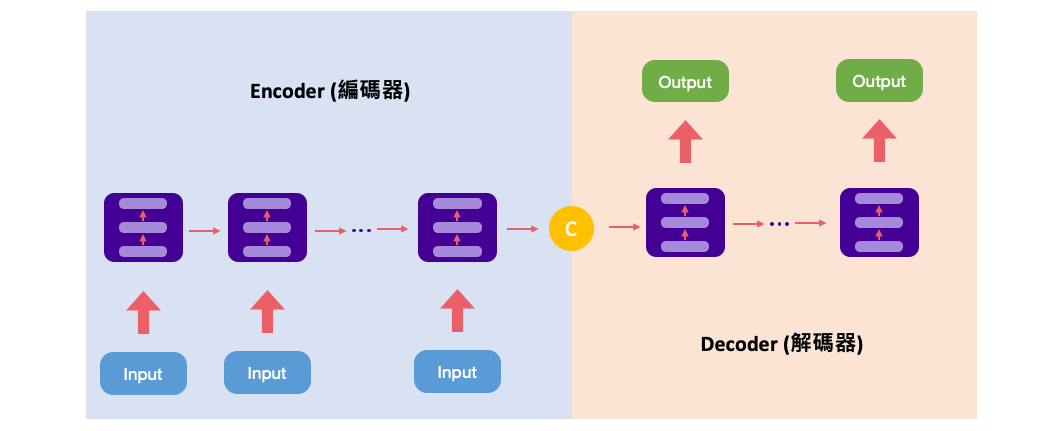
還有一種做法是將 c 當做每一步輸入。
Encoder-Decoder 結構應用範圍主要有:
- 機器翻譯
- 語音識別
- 閱讀理解
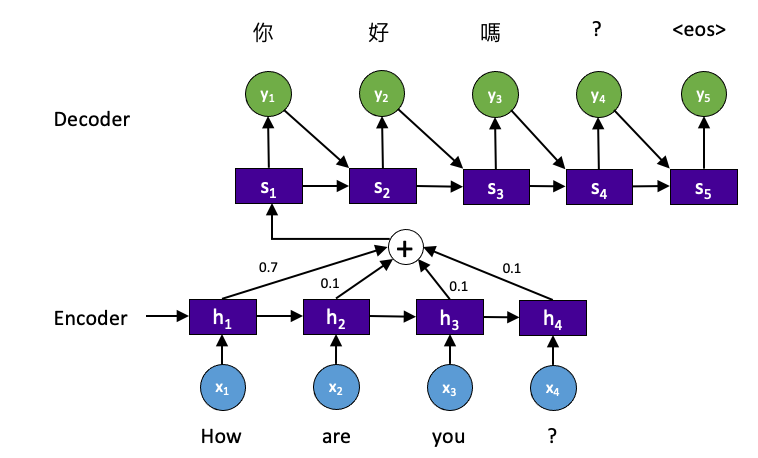
Attention 機制 (RNN+Attention)
在 Encoder-Decoder 中,Encoder 編碼得到序列特徵 c,這組 c 包含序列中所有重要的訊息。當輸入序列較長時,意味著訊息資料量較多。一個向量 c 可能保存所有輸入的重要訊息,因此 c 的長度就成了限制模型的瓶頸,這樣可能會造成欠擬合發生。舉個例子,在機器翻譯中 “I am a boy.” 的 “I” 對 target 中 “我” 的結果影響很大,而其他單詞的影響基本上沒有。因此 Attention 機制在 Decoder 部分每個時間序列輸入不同的 c 解決這個問題。
Reference
下篇文章
[AI學習筆記] 李宏毅課程 Self-Attention 機制解說
如果你對 AI 和深度學習有興趣,歡迎參考我的免費線上電子書《深度學習與神經網路》。這本書涵蓋了許多實用的深度學習知識與技巧,適合任何對此領域有興趣的讀者。內容集結了多位專家的教學資源,例如台大李弘毅教授的課程筆記。點擊下方連結即可獲取最新內容,讓我們一起探索 AI 的世界!
👉 全民瘋 AI 系列《深度學習與神經網路》 - 免費線上電子書
👉 其它全民瘋 AI 系列 - 匯集多主題的 AI 免費電子書
鼓勵持續創作,支持化讚為賞!透過下方的 Like 拍手👏,讓創作者獲得額外收入~
 https://www.youtube.com/channel/UCSNPCGvMYEV-yIXAVt3FA5A
https://www.youtube.com/channel/UCSNPCGvMYEV-yIXAVt3FA5A