前言
本論文提出一個以零為中心的高斯雜訊 (zero centered Gaussian noise) 來產生一個虛假的另一個類別在 latent space。透過交叉商計算誤差學習一條邊界來完整達到一元分類的需求。在此方法中,我們可以拿一個事先預訓練好的 CNN 模型當做基底網路。訓練一個可以分類一個種類的物件,可以應用在人臉辨識、瑕疵檢測、新奇點和離群值檢測。以新奇點偵測來說,假設我們有一堆狗的相片,我們的目標就是要讓模型辨識輸入的照片是否為狗。
- UMDAA-02 Face (user authentication)
- Abnormality1001 (abnormality detection)
- FounderType-200 (novelty detection)
介紹
多元分類需要事先將預訓練的資料進行分類的標籤,相反的一元分類是要辨識此資料是否為目標物 (positive class data or target class data)。一元分類困難的原因是我們有大量的目標種類資料,但是負類(negative class)在現實生活中太多了,只要是任何的一個非目標物都算是負類。因次模訓練的過程中僅有目標種類的資料。一元分的的方法有多種例如:OC-SVM、SVDD(Support Vector Data Description)、MPM(Minimax Probability Machines)
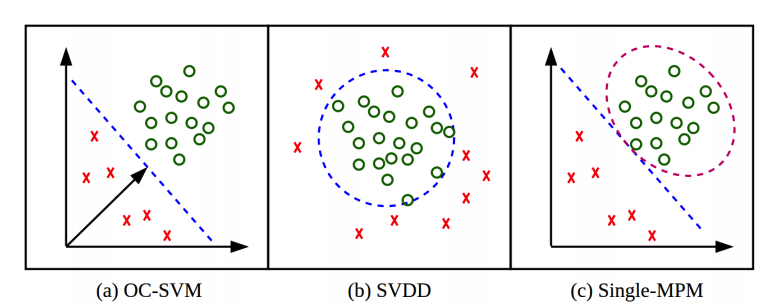
(a) OC-SVM, maximizing the margin of a hyperplane with respect to the origin. (b) SVDD, finding a hypersphere that encloses the given data. (c) MPM, finding a hyperplane that minimizes the misclassification probability.
在過去幾年中物件辨識與偵測的問題隨著深度卷積神蹟網路的出現有大幅的提升,下圖為OC-CNN 網架構圖。分為兩個網路架構,第一個為 VGG16 為基底的特徵萃取網路(4096 embedding),第二個網路是全連階層的分類器。其中需注意的是 VGG16 預訓練網路的最後三層全連階層捨去,這裡只要取得特徵萃取結果作為 embedding。此外在模型訓練過程中除了取得 VGG16 的萃取特徵外,我們還要產生出相同維度的虛擬資料作為負樣本,負樣本的生成是透過 zero centered Gaussian 產生。此問題為二元分類 1 代表目標種類資料,反之 0 表示負種類資料。
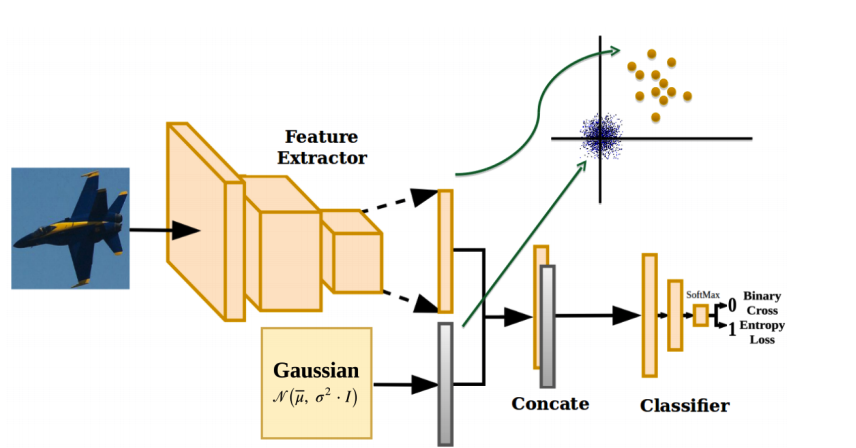
Feature Extractor
任何一個預訓練的 CNN 模型都可以拿來當成特徵萃取器。此範例是採用 VGG16 並移除最後三層全連接分類器作為特徵萃取。整個神經網路是一個 end to end 可訓練的神經網路。 VGG16 網路也可以自由選擇是否可訓練,但在論文中是將預訓練網路的卷積層凍結起來。

Classfication Network
由於在訓練過程中每一筆正樣本(目標資料)會產生一組負樣本,所以在訓練階段會有兩倍的資料量。
Reference
完整 Code 可以從我的 GitHub 中取得!
鼓勵持續創作,支持化讚為賞!透過下方的 Like 拍手👏,讓創作者獲得額外收入~ https://www.youtube.com/channel/UCSNPCGvMYEV-yIXAVt3FA5A
https://www.youtube.com/channel/UCSNPCGvMYEV-yIXAVt3FA5A