什麼是強化學習?
今天我們將討論機器學習中的另一個重要分支——強化學習(Reinforcement Learning)。強化學習是一類特殊的算法。簡單來說,計算機從一開始什麼都不知道,腦中一片空白,透過不斷的嘗試與錯誤學習,最終找到規律,學會如何達成目標。這就是強化學習的基本流程。
現實生活中有許多強化學習的例子。最有名的例子莫過於AlphaGo,這台機器首次在圍棋比賽中擊敗了人類頂尖棋手。還有讓計算機自學如何玩經典遊戲Atari的案例,這些都是透過不斷嘗試、更新行為準則,讓計算機學會下圍棋或在遊戲中獲得高分的過程。
機器人是如何學習的呢?
其實,機器人也需要一位虛擬的老師。不過,這位老師很吝嗇。他不會告訴你應該如何行動或做決定,他唯一做的就是為你的行為打分。那麼,計算機如何從分數中學習如何做決策呢?其實很簡單,只要記住那些高分和低分對應的行為,下一次就使用能獲得高分的行為,避免那些導致低分的行為。

舉個例子,假設這位老師會根據我的開心程度給我打分。當我開心時,我會得到高分;當我不開心時,我則會得到低分。有了這些打分經驗後,我就能知道,為了得到高分,我應該選擇一張開心的臉,避免選擇傷心的臉。這正是強化學習的核心思想——通過分數學習如何做出最佳決策。

分數在強化學習中的重要性
在強化學習中,分數的作用十分重要,因為強化學習具有分數導向性。這個概念類似於監督學習中的正確標籤。我們知道,監督學習已經有了數據與對應的標籤,例如通過訓練學習哪些臉對應哪些標籤。但是,強化學習走得更遠——一開始它並沒有任何數據或標籤,而是通過在環境中的不斷嘗試來獲取這些數據與標籤,然後再學習如何選擇能夠帶來高分的行為(例如選擇開心臉)。
典型的強化學習架構
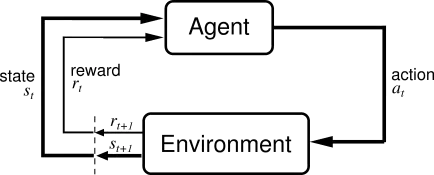
- Agent(代理人)
- 定義:代理人是學習者與決策者,在強化學習中執行動作並學習如何在環境中達成目標。
- 角色:它根據環境的狀態(State)選擇動作(Action),並根據從環境獲得的回饋(Reward)來更新策略或價值函數。
- Environment(環境)
- 定義:環境是代理人所互動的外部世界。它接受代理人執行的動作並根據其做出回應,更新狀態並提供回報。
- 角色:環境接收代理人的動作,並返回下一個狀態和相應的回報。
- Action(動作)
- 定義:動作是代理人在每個狀態下可以選擇的一組行為。這些行為由策略決定。
- 角色:代理人根據當前策略選擇某個動作來影響環境。
- State(狀態)
- 定義:狀態是代理人在某一時刻對環境的描述,包含環境中代理人的位置或情況。
- 角色:狀態幫助代理人決策,並且狀態隨著代理人執行動作而改變。
-
Reward(回報)
- 定義:回報是環境根據代理人的動作給出的反饋,通常為一個標量值。它用來衡量動作的好壞。
- 角色:代理人通過獲取回報來調整其行為,旨在最大化累積回報。
-
Policy(策略)
- 定義:策略是代理人的決策函數,表示從某一狀態到應執行動作的映射。
- 角色:策略控制代理人如何在每個狀態下選擇動作,通常是通過學習來改善的。
- Value Function(價值函數) 定義:價值函數是從狀態到實數的映射,用於評估在某一狀態下,執行一系列動作後可期望獲得的長期回報。 角色:代理人通過價值函數預測未來回報,從而決定最佳策略。
價值(Value)和獎勵(Reward)區別
獎勵(Reward, 𝑟𝑡) 是指在每個時間步驟中,Agent 執行某個動作後,環境立即給予的回饋,這是一個即時的數值。例如,你在迷宮裡走對了一步,可能獲得 +10 的獎勵;如果走錯了一步,可能得到 -5 的懲罰。
價值(Value, 𝑉𝜋(𝑆)) 則是一個累積獎勵的期望值。它衡量的是當 Agent 處於某個狀態時,從該狀態出發,按照某個策略(例如 𝜋)行動,直到最終完成任務所能期望獲得的總獎勵。換句話說,價值是預測未來一系列行動的「總獎勵」,而不僅僅是當下那一步的即時獎勵。
以剛剛迷宮的例子來看:
- 當你在某個位置 𝑆𝑡 向正確的方向移動,你獲得一個 即時獎勵𝑟𝑡=+10。
- 價值𝑉𝜋(𝑆𝑡) 則考慮的是從 𝑆𝑡 開始,未來所有步驟的累積獎勵。例如,未來你可能會獲得50分的累積獎勵,因為你正走向出口。因此,這個位置 𝑆𝑡 的價值可能是 60(包含當前獎勵和未來預期獎勵)。
總結來說:
- 獎勵是當下的回饋,即時的反應。
- 價值是從當前狀態出發,未來整體預期能獲得的累積獎勵。
因此,價值可以被看作是多步驟 累積獎勵 的預期值,而獎勵是每一步的即時反應。
強化學習的算法家族
強化學習是一個龐大的家族,包含了許多不同的算法。例如,有些算法是通過行為的價值來選擇特定行為,像是使用表格學習的Q-Learning和SARSA,或是透過神經網路學習的Deep Q-Network(DQN)。另外還有直接輸出行為的Policy Gradient方法,或者那些透過構建虛擬環境來學習的算法。
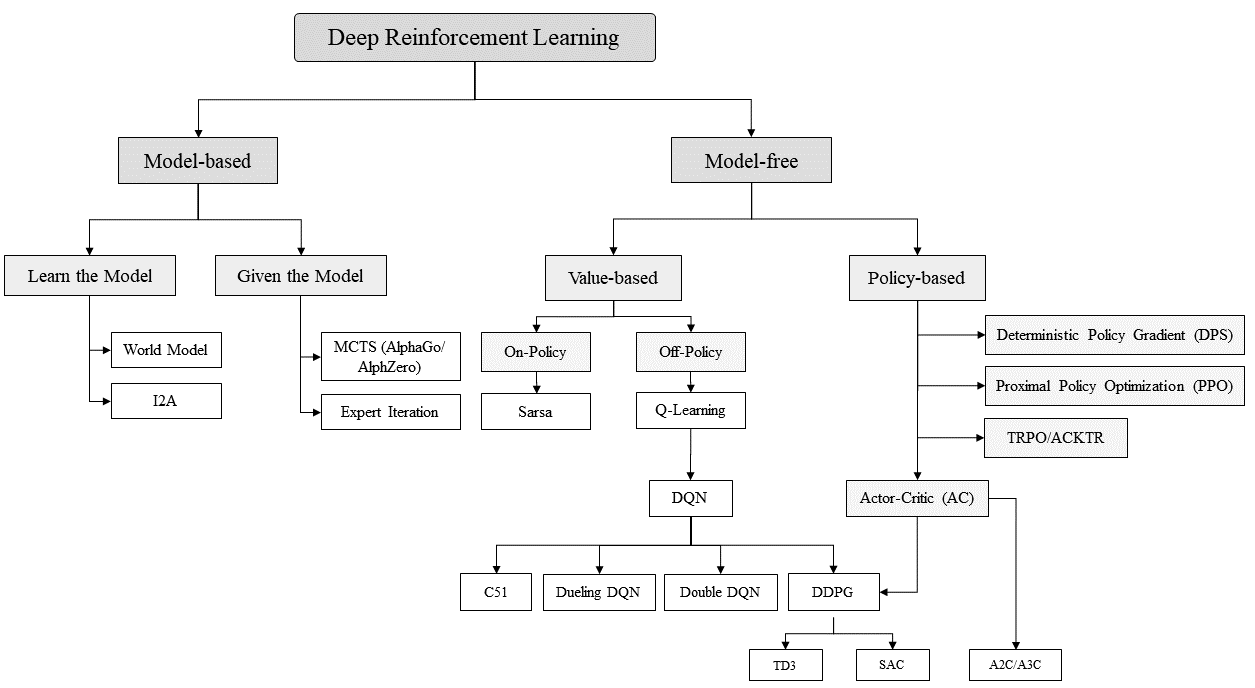
Model-Based RL 與 Model-Free RL
- Model-Based RL:需要環境模型來進行決策或規劃。這類方法會學習一個環境模型或在已知環境模型的基礎上進行操作。
- Model-Free RL:不需要環境模型,僅透過與環境互動來學習。這類方法包括基於策略的學習(Policy-Based)和基於價值的學習(Value-Based)。
Model-Based RL 下的子分類
- Learn the Model:學習環境的模型,再根據模型來進行決策,如World Models、I2A等。
- Given the Model:已知環境模型的情況下直接使用,例如 AlphaZero。
Model-Free RL 下的子分類
- Policy-Based (策略梯度方法): 這類方法直接學習策略,不依賴價值函數。你可以放上 Policy Gradient PPO 和 TRPO。
- Value-Based (基於價值函數的方法): 這類方法透過學習值函數來指導策略。你可以在這裡添加 Q-learning 和 Sarsa,DQN。
- Actor-Critic:混合策略和價值的學習方法 (A2C, A3C)
Policy-Based 和 Value-Based
根據強化學習是以策略為中心還是以值函數為中心分為兩大類Policy-Based和Value-Based如圖:
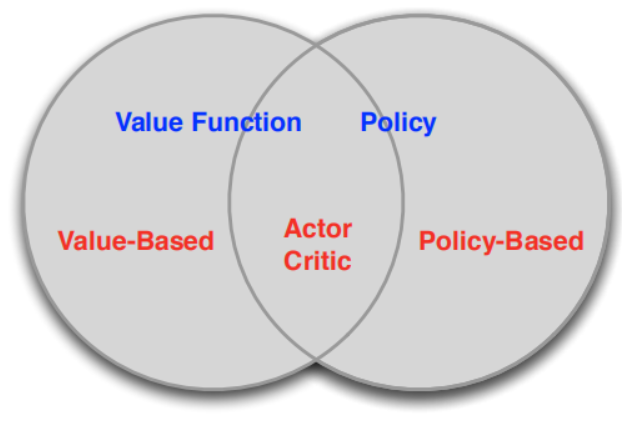
Policy-Based的方法直接輸出下一步動作的概率,根據概率來選取動作。但不一定概率最高就會選擇該動作,還是會從整體進行考慮。適用於非連續和連續的動作。常見的方法有policy gradients。 Value-Based的方法輸出的是動作的價值,選擇價值最高的動作。適用於非連續的動作。常見的方法有Q-learning和Sarsa。 更為厲害的方法是二者的結合:Actor-Critic,Actor根據概率做出動作,Critic根據動作給出價值,從而加速學習過程。